Publications
2026
- Towards Symmetry-sensitive Pose Estimation: A Rotation Representation for Symmetric Object ClassesAndreas Kriegler, Beleznai Csaba, and Margrit GelautzInternational Journal of Computer Vision, 2026
Symmetric objects are common in daily life and industry, yet their inherent orientation ambiguities that impede the training of deep learning networks for pose estimation are rarely discussed in the literature. To cope with these ambiguities, existing solutions typically require the design of specific loss functions and network architectures or resort to symmetry-invariant evaluation metrics. In contrast, we focus on the numeric representation of the rotation itself, modifying trigonometric identities with the degrees of symmetry derived from the objects’ shapes. We use our representation, SARR, to obtain canonic (symmetry-resolved) poses for the symmetric objects in two popular 6D pose estimation datasets, T-LESS and ITODD, where SARR is unique and continuous w.r.t. the visual appearance. This allows us to use a standard CNN for 3D orientation estimation whose performance is evaluated with the symmetry-sensitive cosine distance AR_C. Our networks outperform the state of the art using AR_C and achieve satisfactory performance when using conventional symmetry-invariant measures. Our method does not require any 3D models but only depth, or, as part of an additional experiment, texture-less RGB/grayscale images as input. We also show that networks trained on SARR outperform the same networks trained on rotation matrices, Euler angles, quaternions, standard trigonometrics or the recently popular 6d representation – even in inference scenarios where no prior knowledge of the objects’ symmetry properties is available. Code and a visualization toolkit are available at https://github.com/akriegler/SARR.
@article{Kriegler2026, title = {Towards Symmetry-sensitive Pose Estimation: A Rotation Representation for Symmetric Object Classes}, author = {Kriegler, Andreas and Csaba, Beleznai and Gelautz, Margrit}, journal = {International Journal of Computer Vision}, publisher = {Springer Nature}, year = {2026} }
2024
-
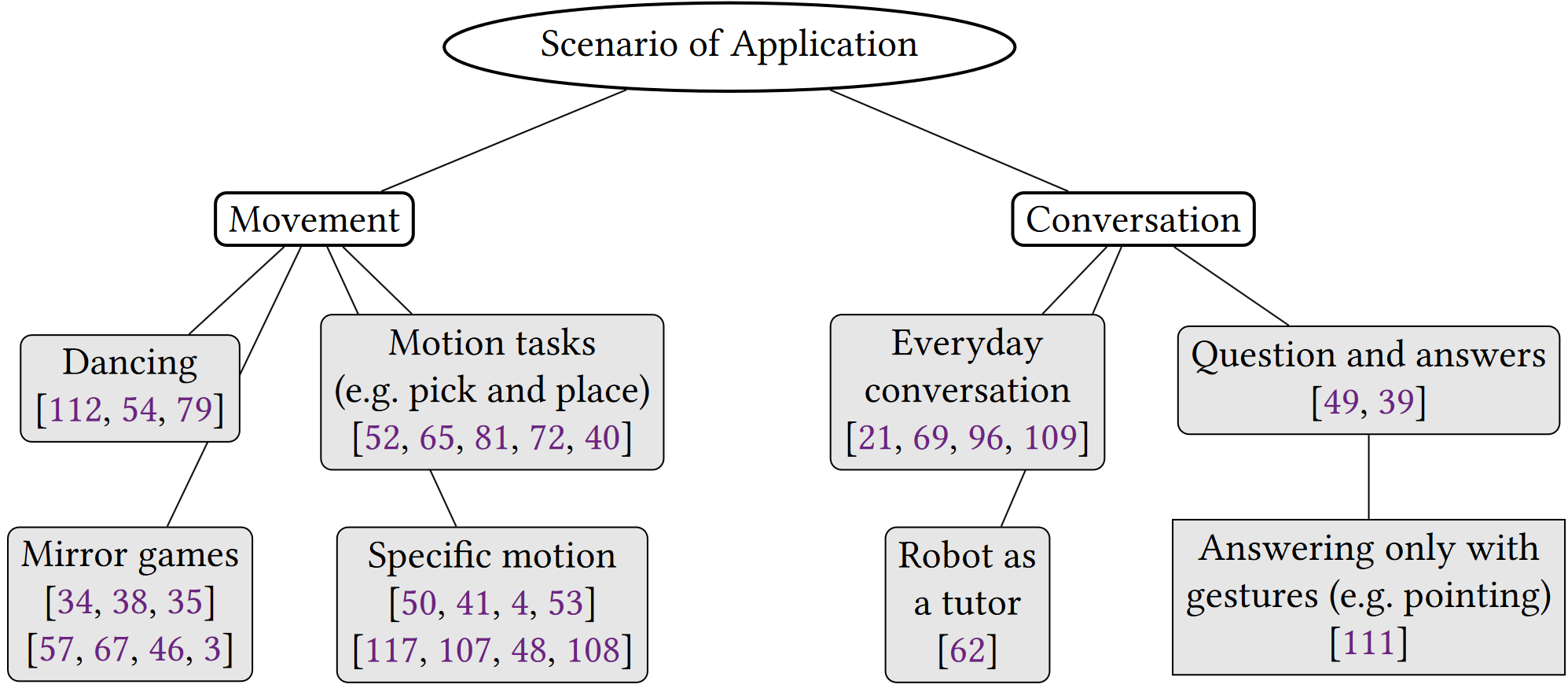 Body Movement Mirroring and Synchrony in Human-Robot InteractionDarja Stoeva, Andreas Kriegler, and Margrit GelautzACM Transactions on Human-Robot Interaction (THRI), 2024
Body Movement Mirroring and Synchrony in Human-Robot InteractionDarja Stoeva, Andreas Kriegler, and Margrit GelautzACM Transactions on Human-Robot Interaction (THRI), 2024This review paper provides an overview of papers that have studied body movement mirroring and synchrony within the field of human-robot interaction. The papers included in this review cover system studies, which focus on evaluating the technical aspects of mirroring and synchrony robotic systems, and user studies, which focus on measuring particular interaction outcomes or attitudes towards robots expressing mirroring and synchrony behaviors. We review the papers in terms of the employed robotic platforms and the focus on parts of the body, the techniques used to sense and react to human motion, the evaluation methods, the intended applications of the human-robot interaction systems and the scenarios utilized in user studies. Finally, challenges and possible future directions are considered and discussed.
@article{Stoeva2024, title = {Body Movement Mirroring and Synchrony in Human-Robot Interaction}, author = {Stoeva, Darja and Kriegler, Andreas and Gelautz, Margrit}, journal = {ACM Transactions on Human-Robot Interaction (THRI)}, volume = {13}, number = {4}, pages = {1--26}, year = {2024}, doi = {10.1145/3682074}, publisher = {Association of Computing Machinery} }
2023
-
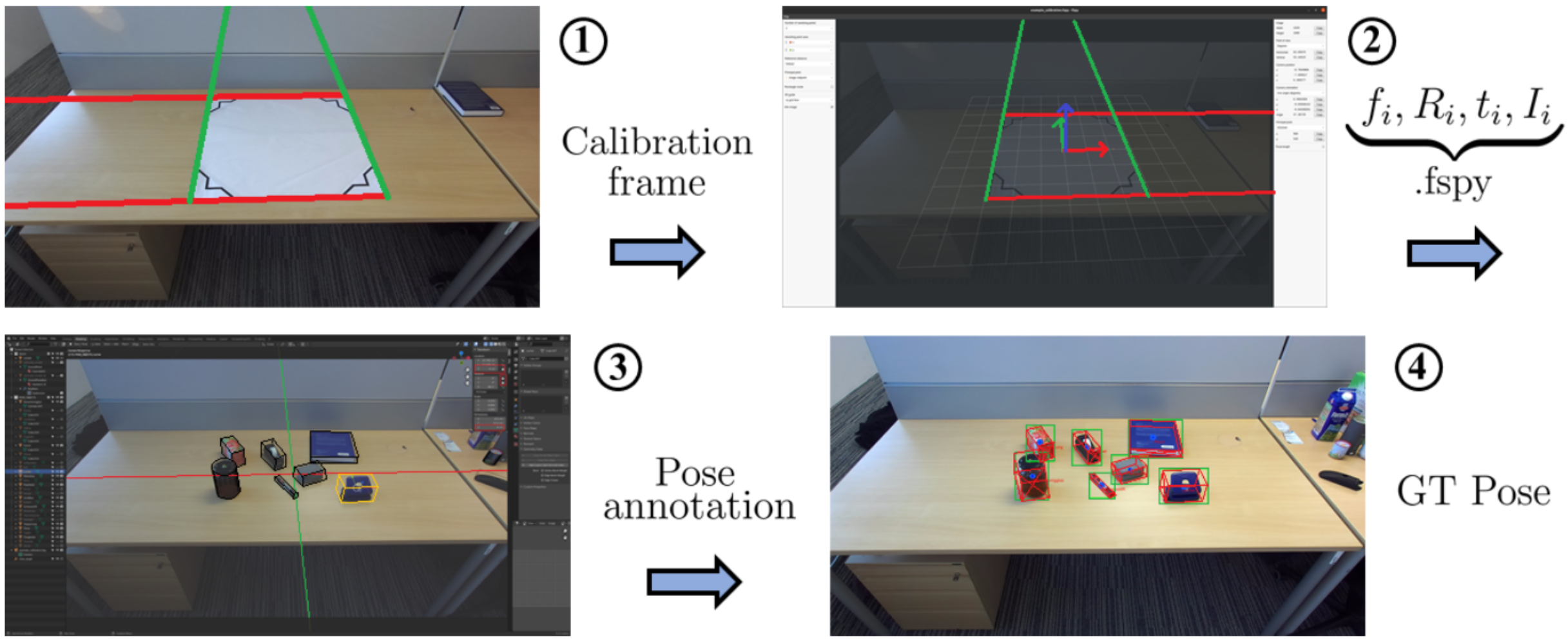 PrimitivePose: Generic Model and Representation for 3D Bounding Box Prediction of Unseen ObjectsAndreas Kriegler, Csaba Beleznai, Margrit Gelautz, Markus Murschitz, and Kai GöbelInternational Journal of Semantic Computing (IJSC), 2023
PrimitivePose: Generic Model and Representation for 3D Bounding Box Prediction of Unseen ObjectsAndreas Kriegler, Csaba Beleznai, Margrit Gelautz, Markus Murschitz, and Kai GöbelInternational Journal of Semantic Computing (IJSC), 2023A considerable amount of research is concerned with the challenging task of estimating three-dimensional (3D) pose and size for multi-object indoor scene con¯gurations. Many existing models rely on a priori known object models, such as 3D CAD models and are therefore limited to a prede¯ned set of object categories. This closed-set constraint limits the range of applications for robots interacting in dynamic environments where previously unseen objects may appear. This paper addresses this problem with a highly generic 3D bounding box detection method that relies entirely on geometric cues obtained from depth data percepts. While the generation of synthetic data, e.g. synthetic depth maps, is commonly used for this task, the well-known synth-to-real gap often emerges, which prohibits transition of models trained solely on synthetic data to the real world. To ameliorate this problem, we use stereo depth computation on synthetic data to obtain pseudo-realistic disparity maps. We then propose an intermediate representation, namely disparity-scaled surface normal (SN) images, which encodes geometry and at the same time preserves depth/scale information unlike the commonly used standard SNs. In a series of experiments, we demonstrate the usefulness of our approach, detecting everyday objects on a captured data set of tabletop scenes, and compare it to the popular PoseCNN model. We quantitatively show that standard SNs are less adequate for challenging 3D detection tasks by comparing predictions from the model trained on disparity alone, SNs and disparity-scaled SNs. Additionally, in an ablation study we investigate the minimal number of training samples required for such a learning task. Lastly, we make the tool used for 3D object annotation publicly available at: https://preview.tinyurl.com/3ycn8v5k. A video showcasing our results can be found at: https://preview.tinyurl.com/dzdzabek.
@article{Kriegler2023, author = {Kriegler, Andreas and Beleznai, Csaba and Gelautz, Margrit and Murschitz, Markus and Göbel, Kai}, title = {PrimitivePose: Generic Model and Representation for 3D Bounding Box Prediction of Unseen Objects}, journal = {International Journal of Semantic Computing (IJSC)}, year = {2023}, volume = {17}, number = {3}, pages = {387--410}, doi = {10.1142/S1793351X23620027}, publisher = {World Scientific Publishing Company} }
2022
-
 Towards Scene Understanding for Autonomous Operations on Airport ApronsDaniel Steininger, Andreas Kriegler, Wolfgang Pointner, Verena Widhalm, Julia Simon, and Oliver ZendelIn Asian Conference on Computer Vision (ACCV) - Workshop on Machine Learning and Computing for Visual Semantic Analysis, 2022
Towards Scene Understanding for Autonomous Operations on Airport ApronsDaniel Steininger, Andreas Kriegler, Wolfgang Pointner, Verena Widhalm, Julia Simon, and Oliver ZendelIn Asian Conference on Computer Vision (ACCV) - Workshop on Machine Learning and Computing for Visual Semantic Analysis, 2022Enhancing logistics vehicles on airport aprons with assistant and autonomous capabilities offers the potential to significantly increase safety and efficiency of operations. However, this research area is still underrepresented compared to other automotive domains, especially regarding available image data, which is essential for training and benchmarking AI-based approaches. To mitigate this gap, we introduce a novel dataset specialized on static and dynamic objects commonly encountered while navigating apron areas. We propose an efficient approach for image acquisition as well as annotation of object instances and environmental parameters. Furthermore, we derive multiple dataset variants on which we conduct baseline classification and detection experiments. The resulting models are evaluated with respect to their overall performance and robustness against specific environmental conditions. The results are quite promising for future applications and provide essential insights regarding the selection of aggregation strategies as well as current potentials and limitations of similar approaches in this research domain.
@inproceedings{Steininger2022, author = {Steininger, Daniel and Kriegler, Andreas and Pointner, Wolfgang and Widhalm, Verena and Simon, Julia and Zendel, Oliver}, title = {Towards Scene Understanding for Autonomous Operations on Airport Aprons}, booktitle = {Asian Conference on Computer Vision (ACCV) - Workshop on Machine Learning and Computing for Visual Semantic Analysis}, year = {2022}, pages = {147--163}, doi = {10.1007/978-3-031-27066-6_11}, publisher = cvf, } -
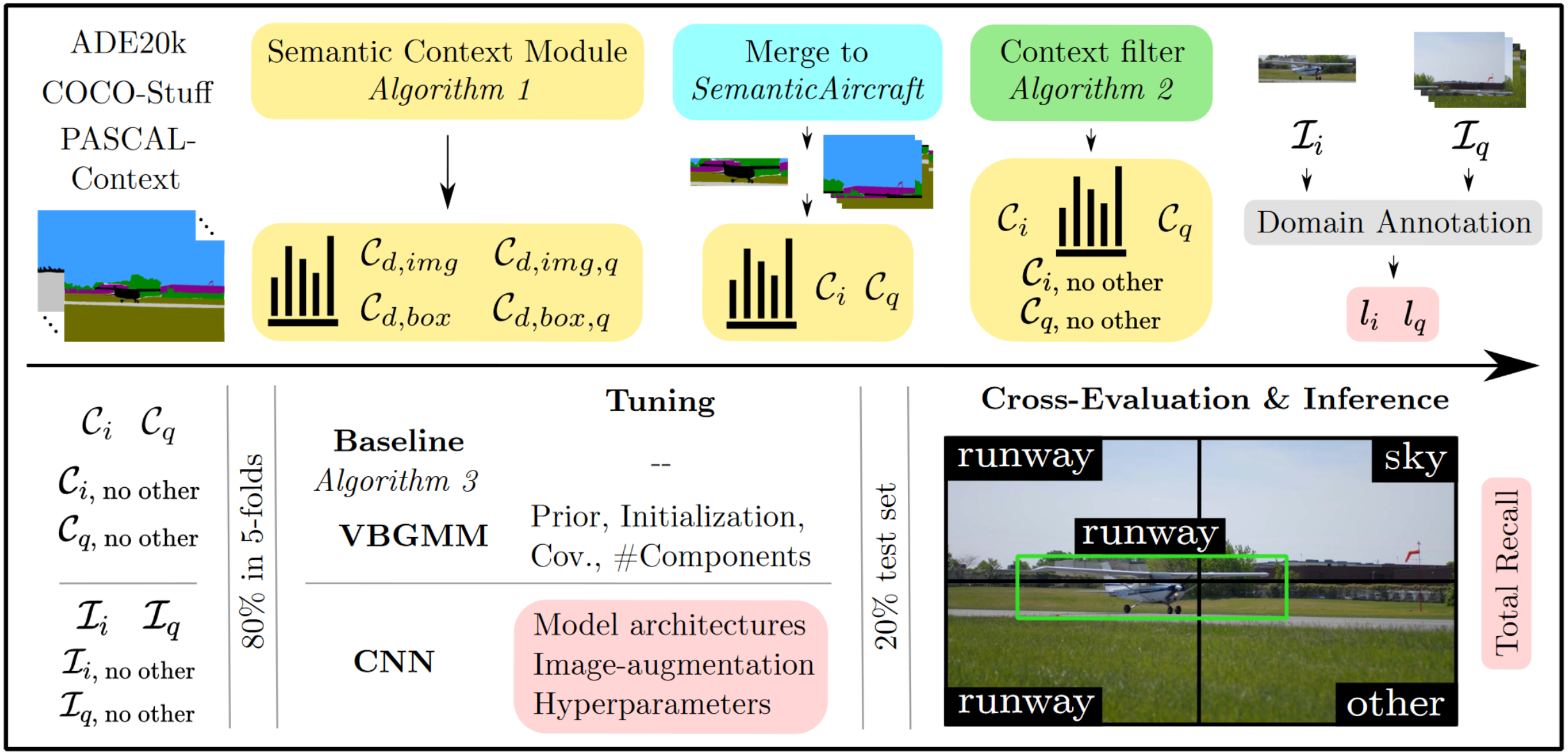 Visual Semantic Context Encoding for Aerial Data Introspection and Domain PredictionAndreas Kriegler, Daniel Steininger, and Wilfried WöberIn Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA), 2022
Visual Semantic Context Encoding for Aerial Data Introspection and Domain PredictionAndreas Kriegler, Daniel Steininger, and Wilfried WöberIn Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA), 2022Visual semantic context describes the relationship between objects and their environment in images. Analyzing this context yields important cues for more holistic scene understanding. While visual semantic context is often learned implicitly, this work proposes a simple algorithm to obtain explicit priors and utilizes them in two ways: Firstly, irrelevant images are filtered during data aggregation, a key step to improving domain coverage especially for public datasets. Secondly, context is used to predict the domains of objects of interest. The framework is applied to the context around airplanes from ADE20K-SceneParsing, COCO-Stuff and PASCAL-Context. As intermediate results, the context statistics were obtained to guide design and mapping choices for the merged dataset SemanticAircraft and image patches were manually annotated in a one-hot manner across four aerial domains. Three different methods predict domains of airplanes: An original threshold-algorithm and unsupervised clustering models use context priors, a supervised CNN works on input images with domain labels. All three models were able to achieve acceptable prediction results, with the CNN obtaining accuracies of 69% to 85%. Additionally, context statistics and applied clustering models provide data introspection enabling a deeper understanding of the visual content.
@inproceedings{Kriegler2022a, author = {Kriegler, Andreas and Steininger, Daniel and Wöber, Wilfried}, title = {Visual Semantic Context Encoding for Aerial Data Introspection and Domain Prediction}, booktitle = {Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA)}, year = {2022}, pages = {433--446}, doi = {10.1007/978-3-031-04881-4_34}, } -
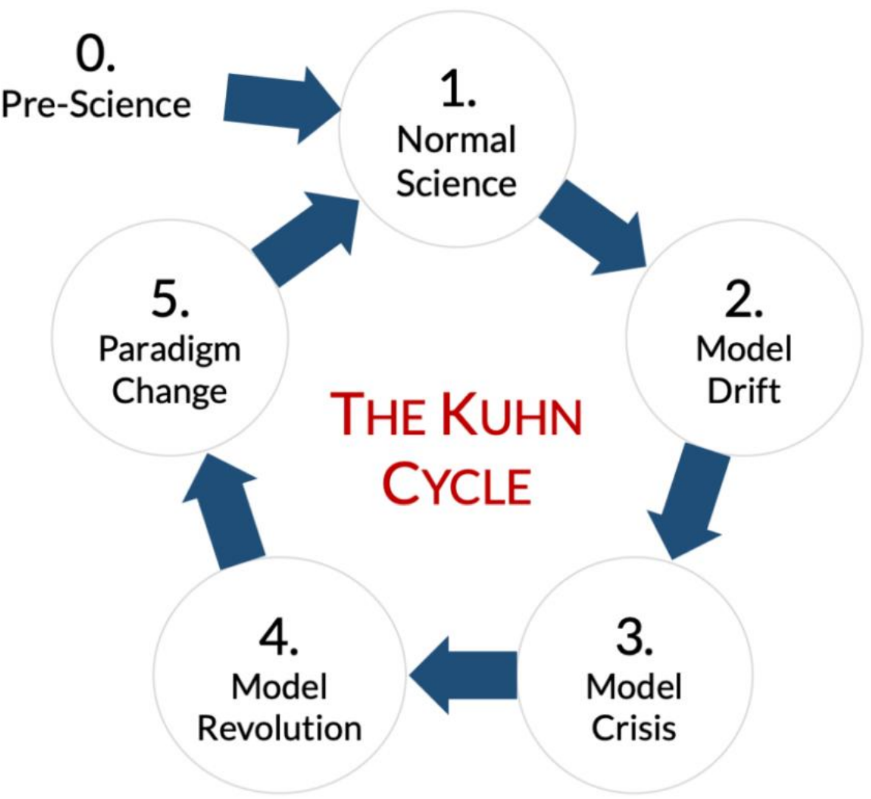 Paradigmatic Revolutions in Computer VisionAndreas KrieglerIn Advances in Neural Information Processing Systems 35 (NeurIPS) - ICBINB: Understanding Deep Learning Through Empirical Falsification, 2022
Paradigmatic Revolutions in Computer VisionAndreas KrieglerIn Advances in Neural Information Processing Systems 35 (NeurIPS) - ICBINB: Understanding Deep Learning Through Empirical Falsification, 2022Kuhn’s groundbreaking Structure divides scientific progress into four phases, the pre-paradigm period, normal science, scientific crisis and revolution. Most of the time a field advances incrementally, constrained and guided by a currently agreed upon paradigm. Creative phases emerge when phenomena occur which lack satisfactory explanation within the current paradigm (the crisis) until a new one replaces it (the revolution). This model of science was mainly laid out by exemplars from natural science, while we want to show that Kuhn’s work is also applicable for information sciences. We analyze the state of one field in particular, computer vision, using Kuhn’s vocabulary. Following significant technology-driven advances of machine learning methods in the age of deep learning, researchers in computer vision were eager to accept the models that now dominate the state of the art. We discuss the current state of the field especially in light of the deep learning revolution and conclude that current deep learning methods cannot fully constitute a paradigm for computer vision in the Kuhnian sense.
@inproceedings{Kriegler2022b, author = {Kriegler, Andreas}, title = {Paradigmatic Revolutions in Computer Vision}, booktitle = {Advances in Neural Information Processing Systems 35 (NeurIPS) - ICBINB: Understanding Deep Learning Through Empirical Falsification}, year = {2022}, } -
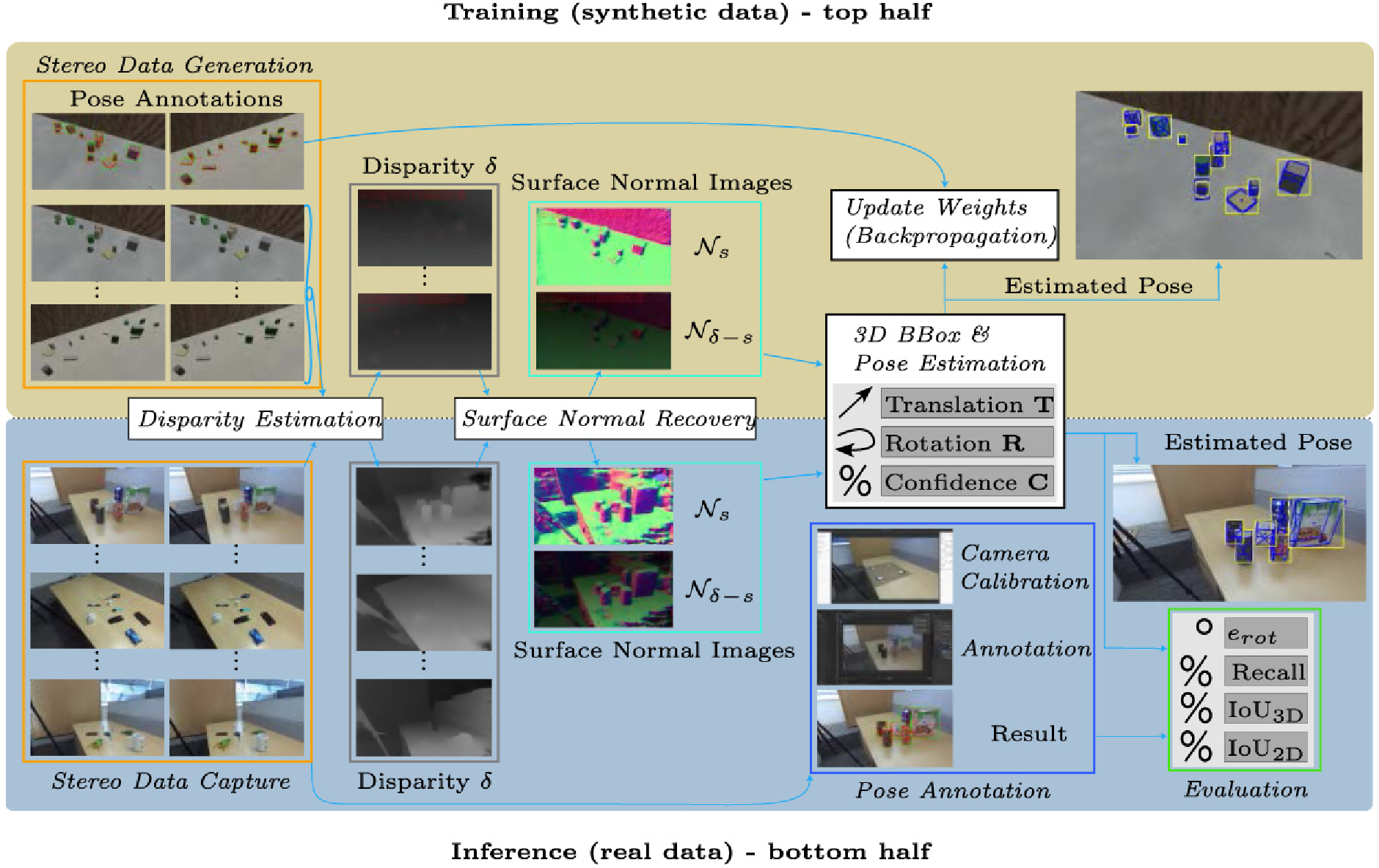 PrimitivePose: 3D Bounding Box Prediction of Unseen Objects via Synthetic Geometric PrimitivesAndreas Kriegler, Csaba Beleznai, Markus Murschitz, Kai Göbel, and Margrit GelautzIn International Conference on Robotic Computing (IRC), 2022
PrimitivePose: 3D Bounding Box Prediction of Unseen Objects via Synthetic Geometric PrimitivesAndreas Kriegler, Csaba Beleznai, Markus Murschitz, Kai Göbel, and Margrit GelautzIn International Conference on Robotic Computing (IRC), 2022This paper studies the challenging problem of 3D pose and size estimation for multi-object scene configurations from stereo views. Most existing methods rely on CAD models and are therefore limited to a predefined set of known object categories. This closed-set constraint limits the range of applications for robots interacting in dynamic environments where previously unseen objects may appear. To address this problem we propose an oriented 3D bounding box detection method that does not require 3D models or semantic information of the objects and is learned entirely from the category-specific domain, relying on purely geometric cues. These geometric cues are objectness and compactness, as represented in the synthetic domain by generating a diverse set of stereo image pairs featuring pose annotated geometric primitives. We then use stereo matching and derive three representations for 3D image content: disparity maps, surface normal images and a novel representation of disparity-scaled surface normal images. The proposed model, PrimitivePose, is trained as a single-stage multi-task neural network using any one of those representations as input and 3D oriented bounding boxes, object centroids and object sizes as output. We evaluate PrimitivePose for 3D bounding box prediction on difficult unseen objects in a tabletop environment and compare it to the popular PoseCNN model – a video showcasing our results can be found at: https://preview.tinyurl.com/2pccumvt.
@inproceedings{Kriegler2022c, author = {Kriegler, Andreas and Beleznai, Csaba and Murschitz, Markus and Göbel, Kai and Gelautz, Margrit}, title = {PrimitivePose: 3D Bounding Box Prediction of Unseen Objects via Synthetic Geometric Primitives}, booktitle = {International Conference on Robotic Computing (IRC)}, year = {2022}, pages = {190--197}, doi = {10.1109/IRC55401.2022.00040}, } -
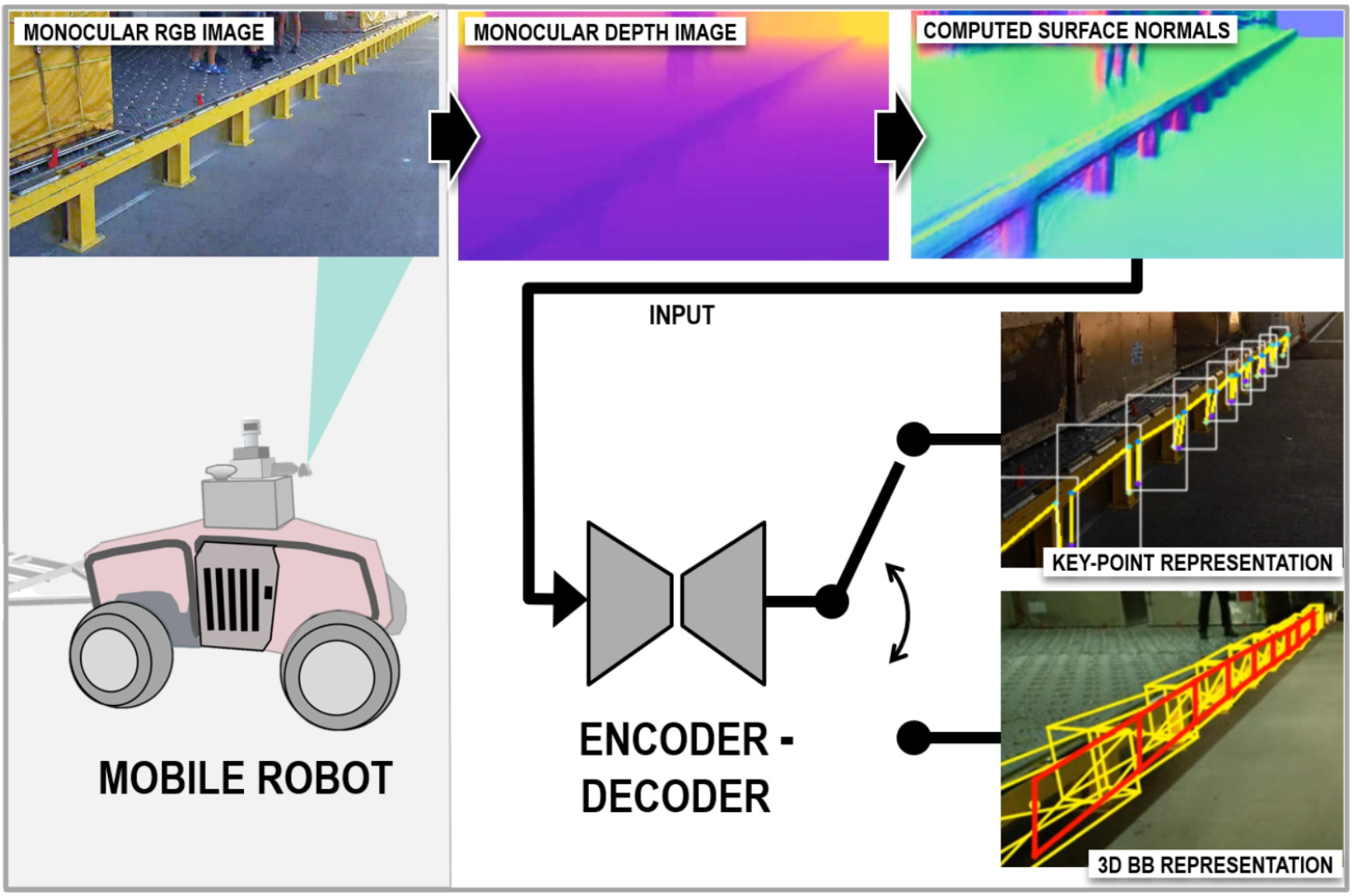 Pose-aware object recognition on a mobile platform via learned geometric representationsCsaba Beleznai, Philipp Ausserlechner, Andreas Kriegler, and Wolfgang PointnerIn Asian Control Conference (ASCC), 2022
Pose-aware object recognition on a mobile platform via learned geometric representationsCsaba Beleznai, Philipp Ausserlechner, Andreas Kriegler, and Wolfgang PointnerIn Asian Control Conference (ASCC), 2022Mobile robot operations are becoming increasingly sophisticated in terms of robust environment perception and levels of automation. However, exploiting the great representational power of data-hungry learned representations is not straightforward, as robotic tasks typically target diverse scenarios with different sets of objects. Learning specific attributes of frequently occurring object categories such as pedestrians and vehicles, is feasible since labeled data-sets are plenty. On the other hand, less common object categories call for the need of use-case-specific data acquisition and labelling campaigns, resulting in efforts which are not sustainable with a growing number of scenarios. In this paper we propose a structure-aware learning scheme, which represents geometric cues of specific functional objects (airport loading ramp) in a highly invariant manner, permitting learning solely from synthetic data, and also leading to a great degree of generalization in real scenarios. In our experiments we employ monocular depth estimation for generating depth and surface normal data and in order to express geometric traits instead of appearance. Using the surface normals, we explore two different representations to learn structural elements of the ramp object and decode its 3D pose: as a set of key-points and as a set of 3D bounding boxes. Results are demonstrated and validated in a series of robotic transportation tasks, where the different representations are compared in terms of recognition and metric space accuracy. Te proposed learning scheme can be also easily applied to recognize arbitrary manmade functional objects (e.g. containers, tools) with and without known dimensions.
@inproceedings{Beleznai2022, author = {Beleznai, Csaba and Ausserlechner, Philipp and Kriegler, Andreas and Pointner, Wolfgang}, title = {Pose-aware object recognition on a mobile platform via learned geometric representations}, booktitle = {Asian Control Conference (ASCC)}, year = {2022}, pages = {175--180}, doi = {10.23919/ascc56756.2022.9828370}, }
2021
-
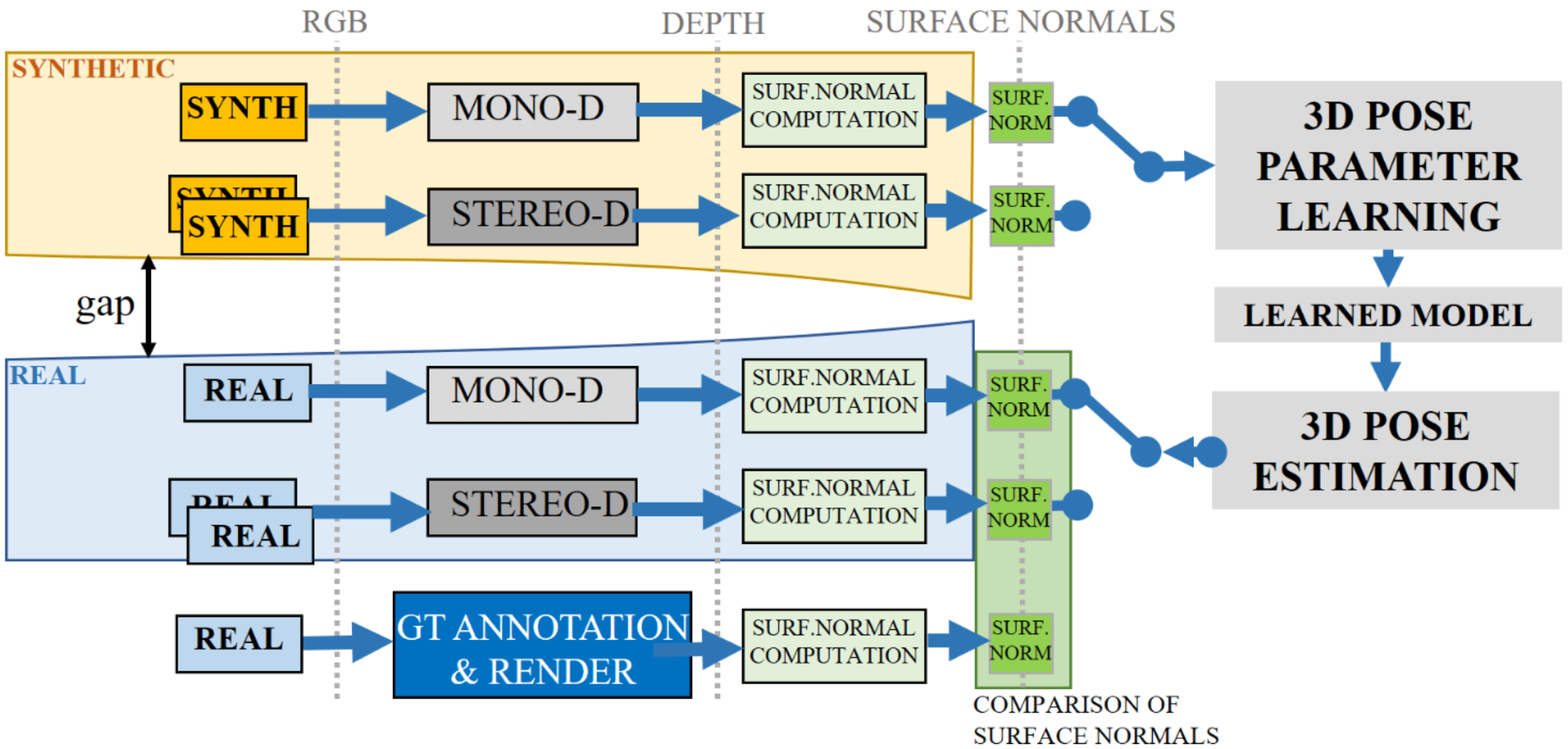 Evaluation of Monocular and Stereo Depth Data for Geometry Assisted Learning of 3D PoseAndreas Kriegler, Csaba Beleznai, and Margrit GelautzIn OAGM workshop, 2021
Evaluation of Monocular and Stereo Depth Data for Geometry Assisted Learning of 3D PoseAndreas Kriegler, Csaba Beleznai, and Margrit GelautzIn OAGM workshop, 2021The estimation of depth cues from a single image has recently emerged as an appealing alternative to depth estimation from stereo image pairs. The easy availability of these dense depth cues naturally triggers research questions, how depth images can be used to infer geometric object and view attributes. Furthermore, the question arises how the quality of the estimated depth data compares between different sensing modalities, especially given the fact that monocular methods rely on a learned correlation between local appearance and depth, without the notion of a metric scale. Further motivated by the ease of synthetic data generation, we propose depth computation on synthetic images as a training step for 3D pose estimation of rigid objects, applying models on real images and thus also demonstrating a reduced synth-to-real gap. To characterize depth data qualities, we present a comparative evaluation involving two monocular and one stereo depth estimation schemes. We furthermore propose a novel and simple two-step depth-ground-truth generation workflow for a quantitative comparison. The presented data generation, evaluation and exemplary pose estimation pipeline are generic and applicable to more complex geometries.
@inproceedings{Kriegler2021, author = {Kriegler, Andreas and Beleznai, Csaba and Gelautz, Margrit}, title = {Evaluation of Monocular and Stereo Depth Data for Geometry Assisted Learning of 3D Pose}, booktitle = {OAGM workshop}, doi = {10.3217/978-3-85125-869-1-01}, year = {2021}, pages = {2--8}, url = {https://publik.tuwien.ac.at/files/publik_300619.pdf}, } -
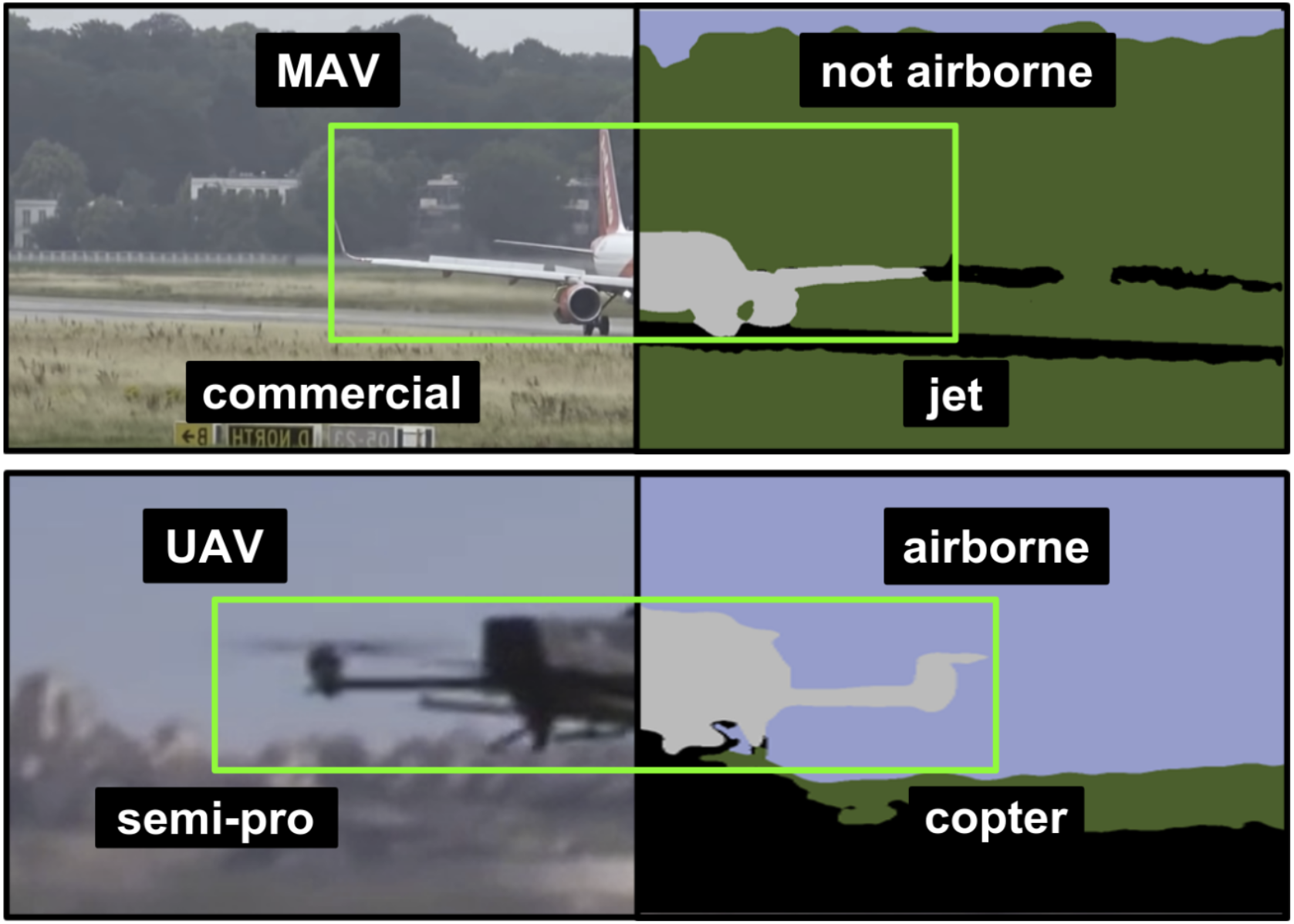 The Aircraft Context Dataset: Understanding and Optimizing Data Variability in Aerial DomainsDaniel Steininger, Verena Widhalm, Julia Simon, Andreas Kriegler, and Christoph SulzbacherIn International Conference on Computer Vision (ICCV) Workshop - 1st Workshop on Airborne Object Tracking, 2021
The Aircraft Context Dataset: Understanding and Optimizing Data Variability in Aerial DomainsDaniel Steininger, Verena Widhalm, Julia Simon, Andreas Kriegler, and Christoph SulzbacherIn International Conference on Computer Vision (ICCV) Workshop - 1st Workshop on Airborne Object Tracking, 2021Despite their increasing demand for assistant and autonomous systems, the recent shift towards data-driven approaches has hardly reached aerial domains, partly due to a lack of specific training and test data. We introduce the Aircraft Context Dataset, a composition of two intercompatible large-scale and versatile image datasets focusing on manned aircraft and UAVs, respectively. In addition to fine-grained annotations for multiple learning tasks, we define and apply a set of relevant meta-parameters and showcase their potential to quantify dataset variability as well as the impact of environmental conditions on model performance. Baseline experiments are conducted for detection, classification and semantic labeling on multiple dataset variants. Their evaluation clearly shows that our contribution is an essential step towards overcoming the data gap and that the proposed variability concept significantly increases the efficiency of specializing models as well as continuously and purposefully extending the dataset.
@inproceedings{Steininger2021, author = {Steininger, Daniel and Widhalm, Verena and Simon, Julia and Kriegler, Andreas and Sulzbacher, Christoph}, title = {The Aircraft Context Dataset: Understanding and Optimizing Data Variability in Aerial Domains}, booktitle = {International Conference on Computer Vision (ICCV) Workshop - 1st Workshop on Airborne Object Tracking}, year = {2021}, pages = {3823--3832}, doi = {10.1109/ICCVW54120.2021.00426}, }
2020
-
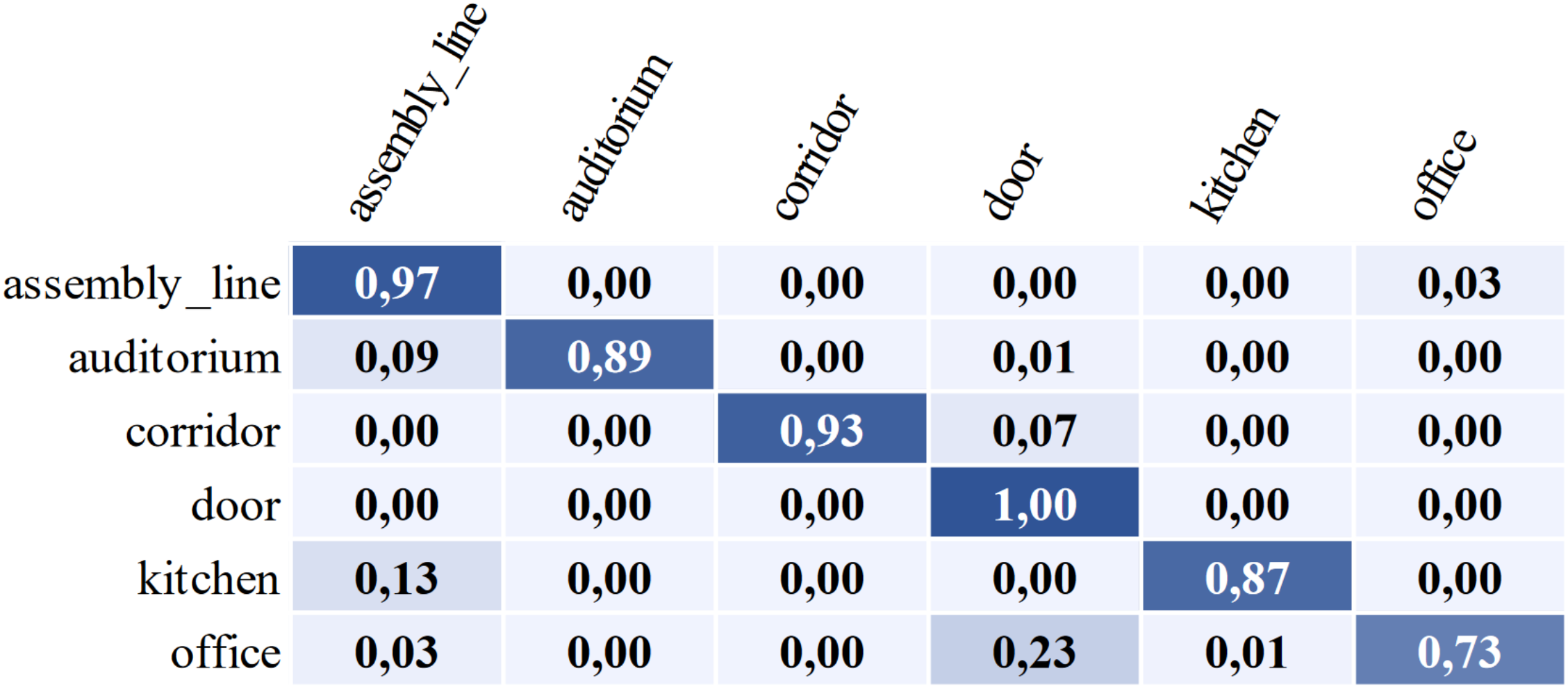 Artificial Neural Networks Based Place CategorizationAndreas Kriegler, Wilfried Wöber, and Mohammed AburaiaIn International Symposium for Production Research (ISPR), 2020
Artificial Neural Networks Based Place CategorizationAndreas Kriegler, Wilfried Wöber, and Mohammed AburaiaIn International Symposium for Production Research (ISPR), 2020Localization using images is a fundamental problem in computer vision for autonomous systems. The information gained enables a high-level understanding of the environment for the mobile robot, which is much more in line with a person’s understanding of their surroundings. It is therefore a critical task for human-robot collaboration and enables robots to find places and identify objects applying this a priori information using semantic maps. Customarily, deep learning models such as convolutional neural networks can be trained for location classification from video streams. However, to achieve acceptable place classification results, previous trained neural nets must be adapted to the specific environment. This work tackles this adaptation of an existing system for place categorization including an extension in terms of possible places. The extension is based on classical machine learning models which were trained based on extracted features of a pre-trained neural network. The developed system outperforms the initial system by correctly classifying 90% of images, including places which were unknown to the neural network.
@inproceedings{Kriegler2020b, author = {Kriegler, Andreas and Wöber, Wilfried and Aburaia, Mohammed}, title = {Artificial Neural Networks Based Place Categorization}, booktitle = {International Symposium for Production Research (ISPR)}, year = {2020}, pages = {201--209}, doi = {10.1007/978-3-030-62784-3_17}, } -
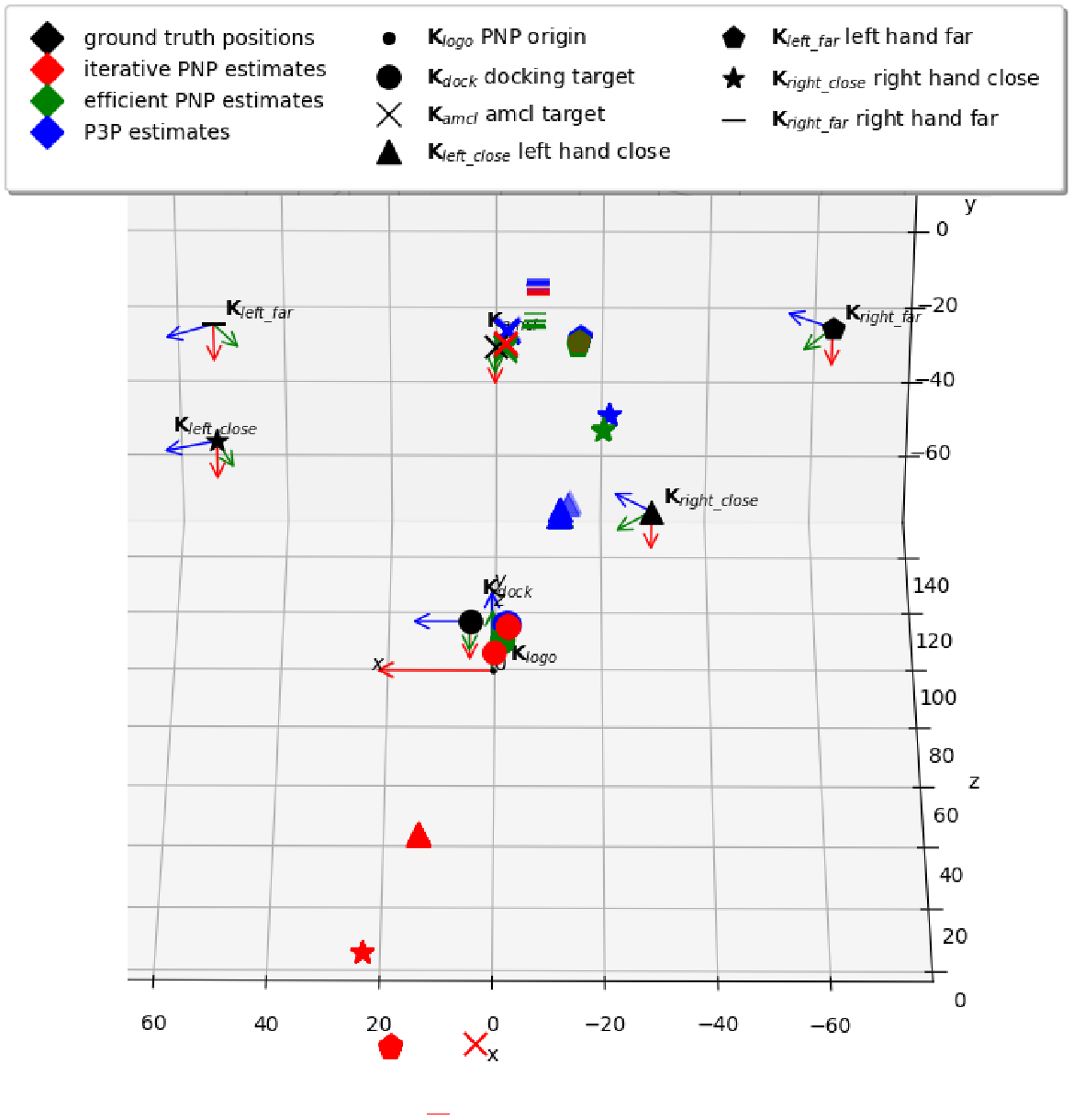 Vision-based Docking of a Mobile RobotAndreas Kriegler and Wilfried WöberIn Joint Austrian Computer Vision and Robotics Workshop (ACVRW), 2020
Vision-based Docking of a Mobile RobotAndreas Kriegler and Wilfried WöberIn Joint Austrian Computer Vision and Robotics Workshop (ACVRW), 2020For mobile robots to be considered autonomous they must reach target locations in required pose, a procedure referred to as docking. Popular current solutions use LiDARs combined with sizeable docking stations but these systems struggle by incorrectly detecting dynamic obstacles. This paper instead proposes a vision-based framework for docking a mobile robot. Faster R-CNN is used for detecting arbitrary visual markers. The pose of the robot is estimated using the solvePnP algorithm relating 2D-3D point pairs. Following exhaustive experiments, it is shown that solvePnP gives systematically inaccurate pose estimates in the x-axis pointing to the side. Pose estimates are off by ten to fifty centimeters and could therefore not be used for docking the robot. Insights are provided to circumvent similar problems in future applications.
@inproceedings{Kriegler2020a, author = {Kriegler, Andreas and Wöber, Wilfried}, title = {Vision-based Docking of a Mobile Robot}, booktitle = {Joint Austrian Computer Vision and Robotics Workshop (ACVRW)}, year = {2020}, pages = {6--12}, doi = {10.3217/978-3-85125-752-6-03}, } -
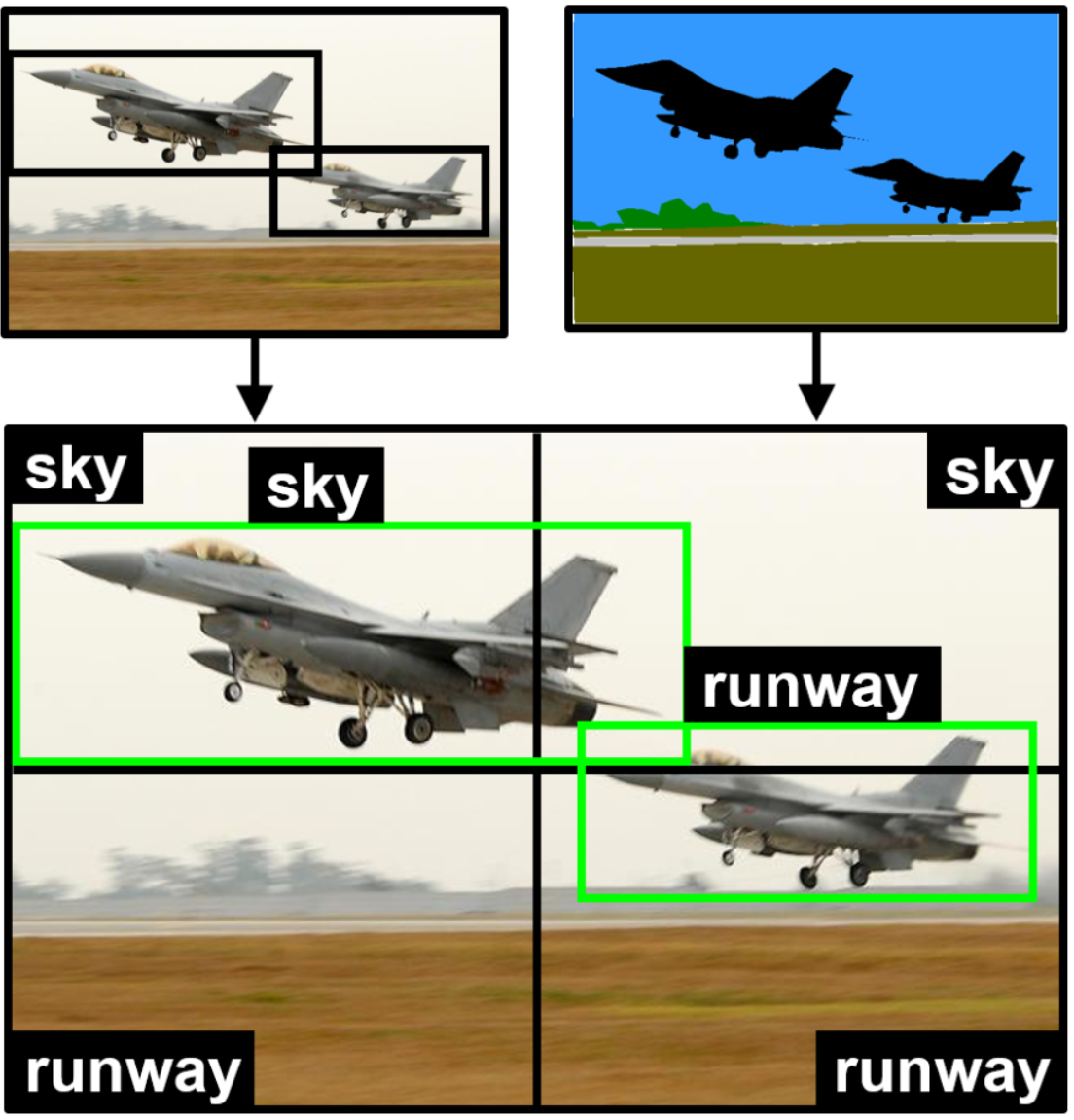 Visual Semantic Context Encoding for Data Harvesting and Domain PredictionAndreas Kriegler2020
Visual Semantic Context Encoding for Data Harvesting and Domain PredictionAndreas Kriegler2020Visual semantic context describes the relationship between objects and their environment in images. Analyzing this context yields important cues for more holistic scene understanding. Domains are an extension of semantic context across multiple images, specified by visual features and form the environment objects most commonly appear in. Humans naturally use these semantic relations to improve their environment perception but in computer vision literature only a handful of works exist that exploit context to significant extent. While context is often learned implicitly in neural networks, this work provides an explicit representation of context and utilizes context statistics in two ways. Using semantic context, irrelevant images can be filtered during data aggregation, a key step to improving domain coverage for a specific learning task, especially working with public datasets. Secondly, context is used to predict the domains of objects of interest, which could enable later model adaptation of fine-tuned models. The framework is applied to the aerial domain, specifically the context around airplanes from ADE20K-SceneParsing, COCO-Stuff and PASCAL-Context. As intermediate results, the context statistics were obtained on these datasets to guide design and label-mapping choices for a merged dataset, referred to as SemanticAircraft in this work. Three different methods were employed to predict domains of airplanes: an original threshold-algorithm and unsupervised clustering via variational Bayesian mixture models use explicit context priors, a supervised CNN on the other hand works on input images with annotated domain-labels. All three models were able to achieve satisfactory prediction results, with the CNN obtaining highest accuracies of 69% to 85% depending on the subset of SemanticAircraft. The results therefore meet expectations – clusters found with the mixture models do not necessarily correspond to the predefined domains and instead allow a more general analysis of the context statistics.
@mastersthesis{Kriegler2020t, author = {Kriegler, Andreas}, title = {Visual Semantic Context Encoding for Data Harvesting and Domain Prediction}, type = {Master's thesis}, school = {University of Applied Sciences Technikum Vienna}, year = {2020}, }
2018
-
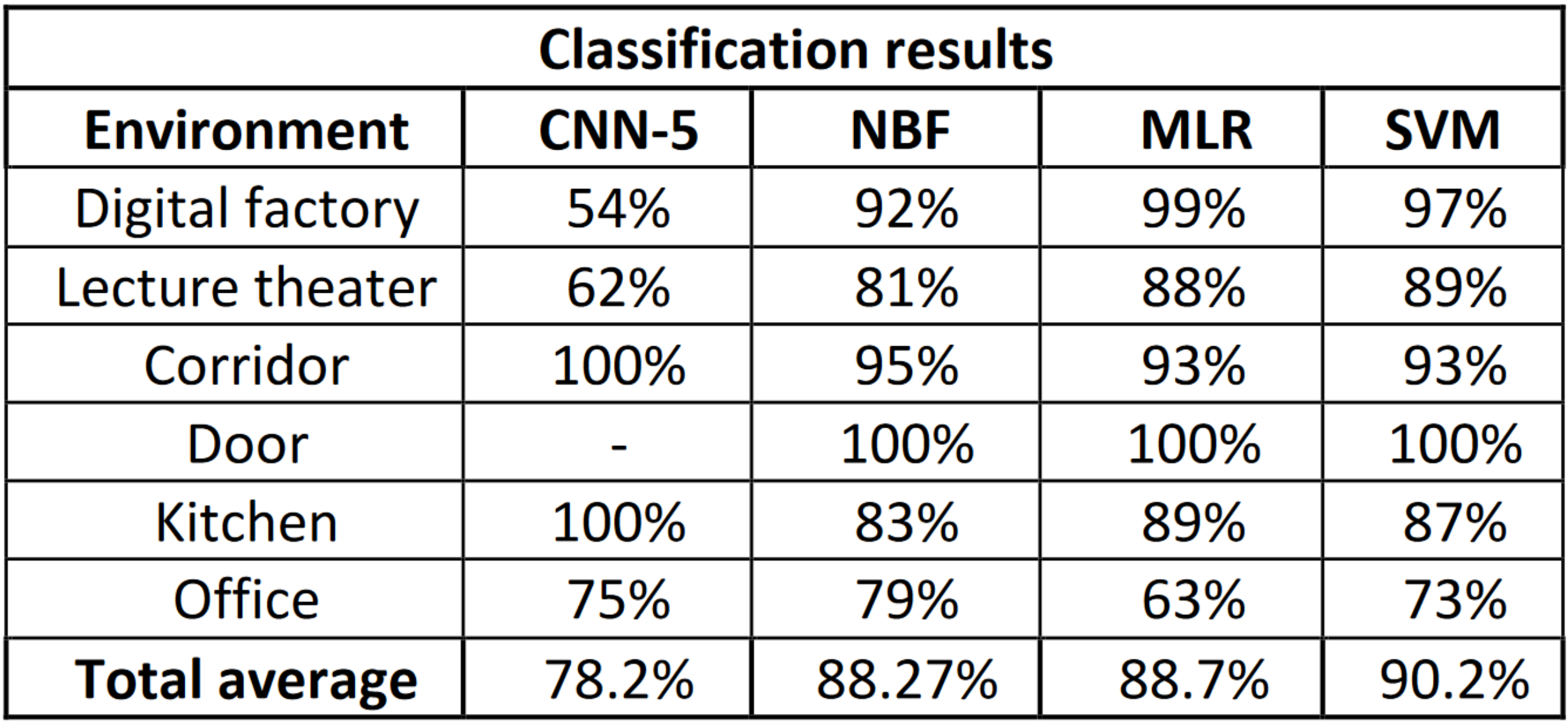 FH Technikum Wien: Artificial Neural Networks Based State Transition Modeling and Place CategorizationAndreas KrieglerIn Konferenz der Mechatronik Plattform Österreich, 2018
FH Technikum Wien: Artificial Neural Networks Based State Transition Modeling and Place CategorizationAndreas KrieglerIn Konferenz der Mechatronik Plattform Österreich, 2018To aid the high-level path-planning decisions of a mobile robot, it has to know not just where it is, but also to identify the type and specifics of that place. Customarily, a deep-learning model such as a convolutional neural network (CNN) is trained to classify the location from a video stream. However, a neural network requires fine-tuning and is limited by the closed-set constraint. Following an extensive research review, the aim was to fine-tune an existing system and extend the set of classes it was trained on. The CNN used for feature extraction has been augmented with machine learning (ML) models which have extended the classification and helped to overcome uncertainties from images showing features of multiple classes. The augmented system outperforms the neural network by correctly classifying 90% of images instead of only 78%
@inproceedings{Kriegler2018, author = {Kriegler, Andreas}, title = {FH Technikum Wien: Artificial Neural Networks Based State Transition Modeling and Place Categorization}, booktitle = {Konferenz der Mechatronik Plattform Österreich}, year = {2018}, pages = {44--45}, } -
 Artificial Neural Networks based State Transition Modeling and Place CategorizationAndreas Kriegler2018
Artificial Neural Networks based State Transition Modeling and Place CategorizationAndreas Kriegler2018To aid the high-level path-planning decisions of a mobile robot, the robotics system has to know not just where the robot is, but also to identify the type and specifics of that place. This is useful in industrial applications such as surveillance and warehousing robots to restrain them to certain environments, but also for human-robot collaboration and consumer service robots, enabling them to find places such as ”kitchen" and get coffee from it, using a semantic map featuring the different class labels. Customarily, a machine- or deep-learning model such as a convolutional neural network is trained to correctly classify the current location from a video stream. However, a neural network requires fine-tuning for proper generalization and is further limited by the closed-set constraint. The foundation of this thesis is an extensive state-of-the-art research to identify applications of neural networks, classic machine learning and control algorithms for state transition modeling and solving classification problems. The aim is to improve the generalization of an existing system used at the Queensland University of Technology for place categorization, and to extend the set of classes known to the system to relax the closed-set constraint. The system in its original state was only capable of classification via the neural network, which did not generalize well enough for immediate usage. The convolutional neural network used for feature extraction of the image stream has been augmented with trained machine learning models such as support vector machines and multi- class logistic regression. The usage of these models has extended the classification to include new place categories that are part of the finite set of classes, has helped to overcome uncer- tainties from images showing features of multiple classes, and has removed the ambiguities introduced by the Random Forest of One-vs-All classifiers employed in the original system. The augmented system outperforms the basic neural network by correctly classifying 90% of images (98% for the three-class environment) instead of only 78%, including a place that the neural network was not trained on. In future projects, the images will be captured by mounting the camera on a mobile robot, the classification will be expanded to all 12 of the distinct places observable on campus, the semantic mapping system will be improved and the knowledge acquired will be used to aid high-level path-planning decisions.
@thesis{Kriegler2018bt2, author = {Kriegler, Andreas}, type = {Bachelor's thesis}, title = {Artificial Neural Networks based State Transition Modeling and Place Categorization}, school = {University of Applied Sciences Technikum Vienna}, year = {2018} } -
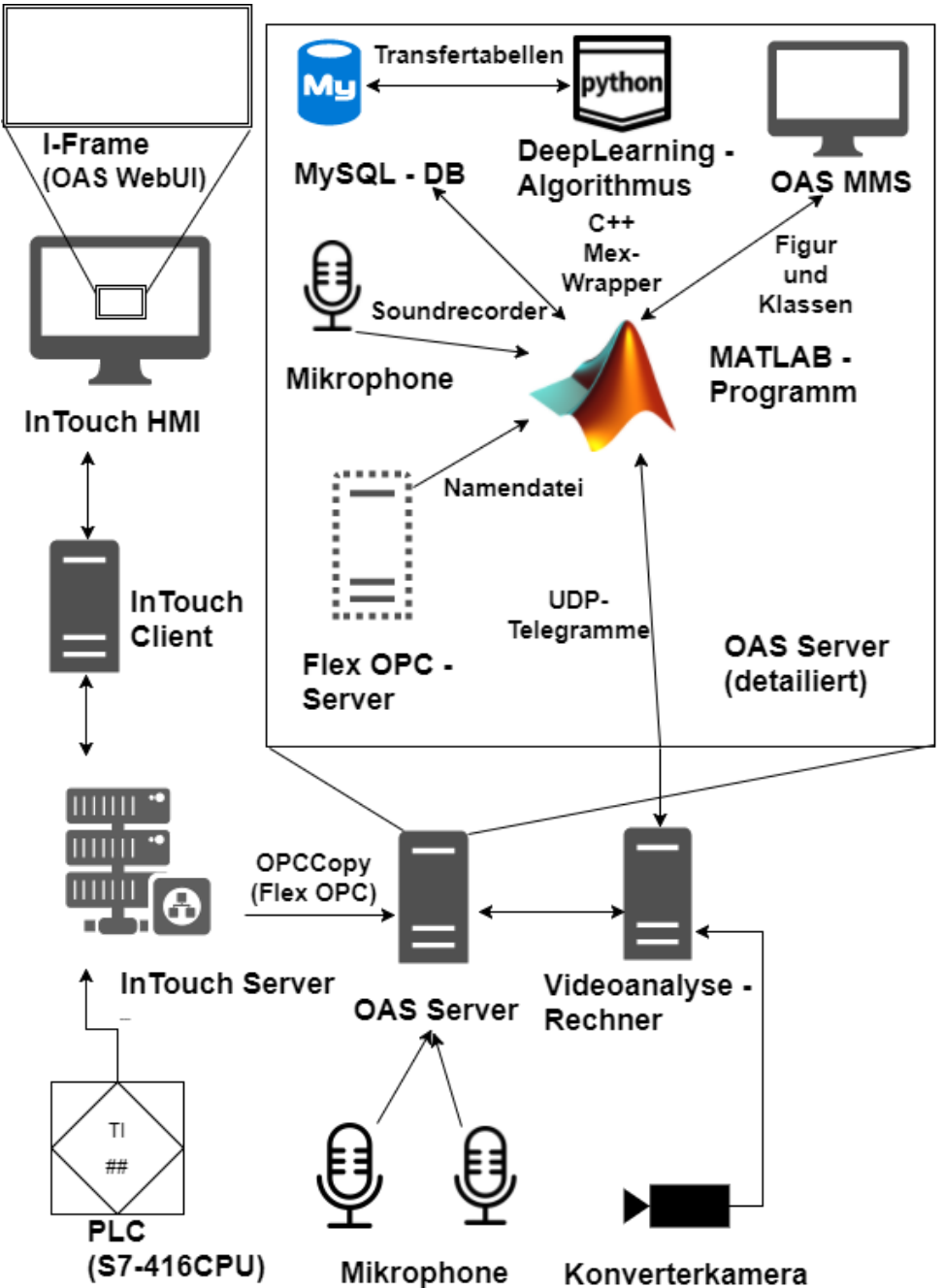 Neuentwicklung der Schlackeauswurferkennung auf der Basis von MATLAB (in German)Andreas Kriegler2018
Neuentwicklung der Schlackeauswurferkennung auf der Basis von MATLAB (in German)Andreas Kriegler2018Basic Oxygen Steelmaking is the most popular method of steelmaking in the world. It uses Basic Oxygen Furnaces (BOFs for short) to blow pure oxygen at supersonic speed onto the surface of the molten pig iron to oxidize the carbon and create steel. During this process slag is being created, which fills the converter. When it cannot be contained in the vessel any longer it is forced out through the opening at the top. This event is called slopping and it pollutes the surrounding environment and reduces the amount of steel yielded by the process. To avoid slopping, the person in charge of the process, refered to as the blower, needs to be provided with accurate results of a slopping-forecast and slopping-detection system. They can then take actions to lower the level of slag within the vessel. Such a system has been developed in graphical programming (LabVIEW) numerous years ago and it displays analysis data from optoacoustical measurement devices. Nonetheless, this system is nowhere near the current state-of-the-art regarding both the Frontend and Backend functionalities. The slopping-prediction is unreliable, and the human-machine interface (HMI) does not follow the new companywide styleguide. Therefore, a new system is being developed in this thesis, which provides the blower with an intuitive User Interface of the process. Furthermore, multiple techniques for slopping-prediction and detection are combined in this system. An in-house MATLAB-framework is used for the basis of the program, in which modern object- oriented programming techniques are prevalent. Interfaces with various components of the system, such as two microphones, a camera, the Programmable Logic Controller (PLC) and a database, are being developed and simulated. Following the styleguide, a clearly arranged HMI is created and thoroughly tested. A complex machine-learning algorithm, which uses both static and dynamic process data, is integrated into the system. Even though the system could not be tested in real plant conditions, the simulations and results were promising. With this algorithm, slopping could be detected in more than 85 out of a 100 analyzed heats.
@thesis{Kriegler2018bt1, author = {Kriegler, Andreas}, title = {Neuentwicklung der Schlackeauswurferkennung auf der Basis von MATLAB (in German)}, type = {Bachelor's thesis}, school = {University of Applied Sciences Technikum Vienna}, year = {2018} }